有一个实例来辅助分析话会更方便,这里使用的实例是:编程找出文件中符合正则表达式 "alpha[alpha|digit]*" 和 "digit+" 的字符串。alpha 就是字母啦:[a-zA-Z];digit就是数字:[0-9]。
先画出DFA:
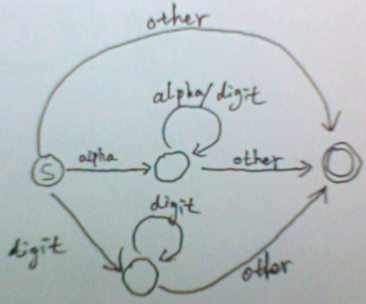
在上图中,状态只有三个(结束状态可以省略):开始状态、单词状态和数字状态。
接下来要用两种不同的方法来实现这个DFA,第一种是传统的 while&switch 大法,第二种是现在流行的设计模式中的状态模式。
为了方便比较,先抽象出一个名为Parser的接口,它提供了一个名为 parse 的方法,传统状态机和状态机模式通过实现这个方法来完成对正则表达式的识别。传统状态机实现的类名叫ClassicalMachine,状态机模式的类名则叫PatternMachine。
Parser接口的定义:
public interface Parser {
void parse() throws Exception ;
}
ClassicalMachine 类的实现非常简单,它在 parse() 方法里就完成了干完了一切:
public class ClassicalMachine implements Parser {
private BufferedReader mFin;
private String mToken;
public ClassicalMachine( BufferedReader fin ) {
mFin = fin;
}
private enum STATUS {START, IS_KEYWORD, IS_NUMBER};
STATUS mStatus = STATUS.START;
@Override
public void parse() throws Exception {
mToken = "";
while (true) {
int ch = mFin.read();
if (-1 == ch) break;
char c = (char)ch;
switch (mStatus) {
case START:
if (Character.isLetter(c)) {
mToken += c;
mStatus = STATUS.IS_KEYWORD;
}
else if (Character.isDigit(c)) {
mToken += c;
mStatus = STATUS.IS_NUMBER;
}
break;
case IS_KEYWORD:
if (Character.isLetterOrDigit(c)) {
mToken += c;
}
else {
mStatus = STATUS.START;
System.out.println("keyword: " + mToken);
mToken = "";
}
break;
case IS_NUMBER:
if (Character.isDigit(c)) {
mToken += c;
}
else {
mStatus = STATUS.START;
System.out.println("number: " + mToken);
mToken = "";
}
break;
}
}
}
}
注意上面有一堆 case xxx: 和 if(xxx),如果DFA中有更多的状态和动作的话,case xxx: 会更多。
接下来实现状态模式类。从DFA图可以看出需要实现的动作只有三个,这三个动作分别在碰到字母、数字和其它字符时触发,因此可以定义状态抽象类如下:
abstract class State {
public abstract void isAlpha(char c);
public abstract void isDigit(char c);
public abstract void isOther(char c);
}
为了方便判断字符是数字还是字母,再加上一个函数dispatch(),于是State类最终是这样:
abstract class State {
public abstract void isAlpha(char c);
public abstract void isDigit(char c);
public abstract void isOther(char c);
public void dispatch(char c) {
if (Character.isLetter(c)) {
isAlpha(c);
}
else if (Character.isDigit(c)) {
isDigit(c);
}
else {
isOther(c);
}
}
}
再看看上面的DFA图,发现状态只有三个,因此接下来从 State 派生出三个类对应这三个状态:
class StartState extends State {
public void isAlpha(char c) {
setState( mKeywordState );
mToken += c;
}
public void isDigit(char c) {
setState( mNumberState );
mToken += c;
}
public void isOther(char c) {
}
}
class KeywordState extends State {
public void isAlpha(char c) {
mToken += c;
}
public void isDigit(char c) {
mToken += c;
}
public void isOther(char c) {
setState( mStartState );
System.out.println("Keyword: " + mToken);
mToken = "";
}
}
class NumberState extends State {
public void isAlpha(char c) {
setState( mStartState );
System.out.println("Number: " + mToken);
mToken = "";
}
public void isDigit(char c) {
mToken += c;
}
public void isOther(char c) {
setState( mStartState );
System.out.println("Number: " + mToken);
mToken = "";
}
}
万事具备,只欠东风了,剩下的只是将字符流作为燃料,来驱动状态机了:
public void parse() throws Exception {
while (true) {
int ch = mFin.read();
if (-1 == ch) break;
char c = (char)ch;
mState.dispatch( c );
}
}
上面啰啰嗦嗦写了一堆代码,目的就是要对比传统状态机的实现方式和状态模式的区别。传统的实现方式是使用一大块 if&switch 代码,比如说lua的lex;当然也可以对这段铁板代码进行拆分,python的lex就是这么干的,但这样做仅仅只是将那些头痛的switch&if分散到了其它的函数而已,switch&if 和数量并没有减少。更多的条件判断语句会导致更复杂的逻辑,因此要让逻辑变得更简单, 得减少这些判断语句才行---状态模式办到了,它干掉了至少一半的判断语句。它是怎么做到的?
状态机的特点之一:状态是在运行时确定的,这刚好可以通过多态来实现。多态的特点:在运行时对对象进行动态绑定,绑定是由编译器或运行环境来完成的,无需手工参与,因此也可以说是现代越来越强大的编译器or运行环境干掉了switch&if。
附完整的代码:
ClassicalMachine.java:
package bsg;
import java.io.BufferedReader;
import java.io.IOException;
import bsg.Main.Parser;
import com.sun.tools.hat.internal.parser.Reader;
public class ClassicalMachine implements Parser {
private BufferedReader mFin;
private String mToken;
public ClassicalMachine( BufferedReader fin ) {
mFin = fin;
}
private enum STATUS {START, IS_KEYWORD, IS_NUMBER};
STATUS mStatus = STATUS.START;
@Override
public void parse() throws Exception {
mToken = "";
while (true) {
int ch = mFin.read();
if (-1 == ch) break;
char c = (char)ch;
switch (mStatus) {
case START:
if (Character.isLetter(c)) {
mToken += c;
mStatus = STATUS.IS_KEYWORD;
}
else if (Character.isDigit(c)) {
mToken += c;
mStatus = STATUS.IS_NUMBER;
}
break;
case IS_KEYWORD:
if (Character.isLetterOrDigit(c)) {
mToken += c;
}
else {
mStatus = STATUS.START;
System.out.println("keyword: " + mToken);
mToken = "";
}
break;
case IS_NUMBER:
if (Character.isDigit(c)) {
mToken += c;
}
else {
mStatus = STATUS.START;
System.out.println("number: " + mToken);
mToken = "";
}
break;
}
}
}
}
public class ClassicalMachine implements Parser {
private BufferedReader mFin;
private String mToken;
public ClassicalMachine( BufferedReader fin ) {
mFin = fin;
}
private enum STATUS {START, IS_KEYWORD, IS_NUMBER};
STATUS mStatus = STATUS.START;
@Override
public void parse() throws Exception {
mToken = "";
while (true) {
int ch = mFin.read();
if (-1 == ch) break;
char c = (char)ch;
switch (mStatus) {
case START:
if (Character.isLetter(c)) {
mToken += c;
mStatus = STATUS.IS_KEYWORD;
}
else if (Character.isDigit(c)) {
mToken += c;
mStatus = STATUS.IS_NUMBER;
}
break;
case IS_KEYWORD:
if (Character.isLetterOrDigit(c)) {
mToken += c;
}
else {
mStatus = STATUS.START;
System.out.println("keyword: " + mToken);
mToken = "";
}
break;
case IS_NUMBER:
if (Character.isDigit(c)) {
mToken += c;
}
else {
mStatus = STATUS.START;
System.out.println("number: " + mToken);
mToken = "";
}
break;
}
}
}
}
abstract class State {
public abstract void isAlpha(char c);
public abstract void isDigit(char c);
public abstract void isOther(char c);
public void dispatch(char c) {
if (Character.isLetter(c)) {
isAlpha(c);
}
else if (Character.isDigit(c)) {
isDigit(c);
}
else {
isOther(c);
}
}
}
class StartState extends State {
public void isAlpha(char c) {
setState( mKeywordState );
mToken += c;
}
public void isDigit(char c) {
setState( mNumberState );
mToken += c;
}
public void isOther(char c) {
}
}
class KeywordState extends State {
public void isAlpha(char c) {
mToken += c;
}
public void isDigit(char c) {
mToken += c;
}
public void isOther(char c) {
setState( mStartState );
System.out.println("Keyword: " + mToken);
mToken = "";
}
}
class NumberState extends State {
public void isAlpha(char c) {
setState( mStartState );
System.out.println("Number: " + mToken);
mToken = "";
}
public void isDigit(char c) {
mToken += c;
}
public void isOther(char c) {
setState( mStartState );
System.out.println("Number: " + mToken);
mToken = "";
}
}
public void parse() throws Exception {
while (true) {
int ch = mFin.read();
if (-1 == ch) break;
char c = (char)ch;
mState.dispatch( c );
}
}
PatternMachine.java
package bsg;
import java.io.BufferedReader;
import bsg.Main.Parser;
public class PatternMachine implements Parser {
private String mToken = "";
private BufferedReader mFin;
public PatternMachine( BufferedReader fin ) {
mFin = fin;
}
private StartState mStartState = new StartState();
private KeywordState mKeywordState = new KeywordState();
private NumberState mNumberState = new NumberState();
//
private State mState = mStartState;
public State getState() {
return mState;
}
public void setState(State state) {
mState = state;
}
abstract class State {
public abstract void isAlpha(char c);
public abstract void isDigit(char c);
public abstract void isOther(char c);
public void dispatch(char c) {
if (Character.isLetter(c)) {
isAlpha(c);
}
else if (Character.isDigit(c)) {
isDigit(c);
}
else {
isOther(c);
}
}
}
class StartState extends State {
public void isAlpha(char c) {
setState( mKeywordState );
mToken += c;
}
public void isDigit(char c) {
setState( mNumberState );
mToken += c;
}
public void isOther(char c) {
}
}
class KeywordState extends State {
public void isAlpha(char c) {
mToken += c;
}
public void isDigit(char c) {
mToken += c;
}
public void isOther(char c) {
setState( mStartState );
System.out.println("Keyword: " + mToken);
mToken = "";
}
}
class NumberState extends State {
public void isAlpha(char c) {
setState( mStartState );
System.out.println("Number: " + mToken);
mToken = "";
}
public void isDigit(char c) {
mToken += c;
}
public void isOther(char c) {
setState( mStartState );
System.out.println("Number: " + mToken);
mToken = "";
}
}
@Override
public void parse() throws Exception {
while (true) {
int ch = mFin.read();
if (-1 == ch) break;
char c = (char)ch;
mState.dispatch( c );
}
}
}
package bsg;
import java.io.BufferedReader;
import java.io.IOException;
import bsg.Main.Parser;
import com.sun.tools.hat.internal.parser.Reader;
public class ClassicalMachine implements Parser {
private BufferedReader mFin;
private String mToken;
public ClassicalMachine( BufferedReader fin ) {
mFin = fin;
}
private enum STATUS {START, IS_KEYWORD, IS_NUMBER};
STATUS mStatus = STATUS.START;
@Override
public void parse() throws Exception {
mToken = "";
while (true) {
int ch = mFin.read();
if (-1 == ch) break;
char c = (char)ch;
switch (mStatus) {
case START:
if (Character.isLetter(c)) {
mToken += c;
mStatus = STATUS.IS_KEYWORD;
}
else if (Character.isDigit(c)) {
mToken += c;
mStatus = STATUS.IS_NUMBER;
}
break;
case IS_KEYWORD:
if (Character.isLetterOrDigit(c)) {
mToken += c;
}
else {
mStatus = STATUS.START;
System.out.println("keyword: " + mToken);
mToken = "";
}
break;
case IS_NUMBER:
if (Character.isDigit(c)) {
mToken += c;
}
else {
mStatus = STATUS.START;
System.out.println("number: " + mToken);
mToken = "";
}
break;
}
}
}
}
public class ClassicalMachine implements Parser {
private BufferedReader mFin;
private String mToken;
public ClassicalMachine( BufferedReader fin ) {
mFin = fin;
}
private enum STATUS {START, IS_KEYWORD, IS_NUMBER};
STATUS mStatus = STATUS.START;
@Override
public void parse() throws Exception {
mToken = "";
while (true) {
int ch = mFin.read();
if (-1 == ch) break;
char c = (char)ch;
switch (mStatus) {
case START:
if (Character.isLetter(c)) {
mToken += c;
mStatus = STATUS.IS_KEYWORD;
}
else if (Character.isDigit(c)) {
mToken += c;
mStatus = STATUS.IS_NUMBER;
}
break;
case IS_KEYWORD:
if (Character.isLetterOrDigit(c)) {
mToken += c;
}
else {
mStatus = STATUS.START;
System.out.println("keyword: " + mToken);
mToken = "";
}
break;
case IS_NUMBER:
if (Character.isDigit(c)) {
mToken += c;
}
else {
mStatus = STATUS.START;
System.out.println("number: " + mToken);
mToken = "";
}
break;
}
}
}
}
abstract class State {
public abstract void isAlpha(char c);
public abstract void isDigit(char c);
public abstract void isOther(char c);
public void dispatch(char c) {
if (Character.isLetter(c)) {
isAlpha(c);
}
else if (Character.isDigit(c)) {
isDigit(c);
}
else {
isOther(c);
}
}
}
class StartState extends State {
public void isAlpha(char c) {
setState( mKeywordState );
mToken += c;
}
public void isDigit(char c) {
setState( mNumberState );
mToken += c;
}
public void isOther(char c) {
}
}
class KeywordState extends State {
public void isAlpha(char c) {
mToken += c;
}
public void isDigit(char c) {
mToken += c;
}
public void isOther(char c) {
setState( mStartState );
System.out.println("Keyword: " + mToken);
mToken = "";
}
}
class NumberState extends State {
public void isAlpha(char c) {
setState( mStartState );
System.out.println("Number: " + mToken);
mToken = "";
}
public void isDigit(char c) {
mToken += c;
}
public void isOther(char c) {
setState( mStartState );
System.out.println("Number: " + mToken);
mToken = "";
}
}
public void parse() throws Exception {
while (true) {
int ch = mFin.read();
if (-1 == ch) break;
char c = (char)ch;
mState.dispatch( c );
}
}
Main.java
package bsg;
import java.io.BufferedReader;
import java.io.FileNotFoundException;
import java.io.FileReader;
public class Main {
public interface Parser {
void parse() throws Exception ;
}
public static void main(String[] args) {
if (0 == args.length) return;
BufferedReader fin = null;
try {
fin = new BufferedReader( new FileReader(args[1] ) );
} catch (FileNotFoundException e) {
e.printStackTrace();
}
Parser parser = null;
if (args[0].equals("cla")) {
parser = new ClassicalMachine( fin );
} else if (args[0].equals("pat")){
parser = new PatternMachine( fin );
}
long beg = System.currentTimeMillis();
try {
parser.parse();
fin.close();
} catch (Exception e) {
e.printStackTrace();
}
long end = System.currentTimeMillis() - beg;
System.out.println("" + end);
}
}
package bsg;
import java.io.BufferedReader;
import bsg.Main.Parser;
public class PatternMachine implements Parser {
private String mToken = "";
private BufferedReader mFin;
public PatternMachine( BufferedReader fin ) {
mFin = fin;
}
private StartState mStartState = new StartState();
private KeywordState mKeywordState = new KeywordState();
private NumberState mNumberState = new NumberState();
//
private State mState = mStartState;
public State getState() {
return mState;
}
public void setState(State state) {
mState = state;
}
abstract class State {
public abstract void isAlpha(char c);
public abstract void isDigit(char c);
public abstract void isOther(char c);
public void dispatch(char c) {
if (Character.isLetter(c)) {
isAlpha(c);
}
else if (Character.isDigit(c)) {
isDigit(c);
}
else {
isOther(c);
}
}
}
class StartState extends State {
public void isAlpha(char c) {
setState( mKeywordState );
mToken += c;
}
public void isDigit(char c) {
setState( mNumberState );
mToken += c;
}
public void isOther(char c) {
}
}
class KeywordState extends State {
public void isAlpha(char c) {
mToken += c;
}
public void isDigit(char c) {
mToken += c;
}
public void isOther(char c) {
setState( mStartState );
System.out.println("Keyword: " + mToken);
mToken = "";
}
}
class NumberState extends State {
public void isAlpha(char c) {
setState( mStartState );
System.out.println("Number: " + mToken);
mToken = "";
}
public void isDigit(char c) {
mToken += c;
}
public void isOther(char c) {
setState( mStartState );
System.out.println("Number: " + mToken);
mToken = "";
}
}
@Override
public void parse() throws Exception {
while (true) {
int ch = mFin.read();
if (-1 == ch) break;
char c = (char)ch;
mState.dispatch( c );
}
}
}
package bsg;
import java.io.BufferedReader;
import java.io.IOException;
import bsg.Main.Parser;
import com.sun.tools.hat.internal.parser.Reader;
public class ClassicalMachine implements Parser {
private BufferedReader mFin;
private String mToken;
public ClassicalMachine( BufferedReader fin ) {
mFin = fin;
}
private enum STATUS {START, IS_KEYWORD, IS_NUMBER};
STATUS mStatus = STATUS.START;
@Override
public void parse() throws Exception {
mToken = "";
while (true) {
int ch = mFin.read();
if (-1 == ch) break;
char c = (char)ch;
switch (mStatus) {
case START:
if (Character.isLetter(c)) {
mToken += c;
mStatus = STATUS.IS_KEYWORD;
}
else if (Character.isDigit(c)) {
mToken += c;
mStatus = STATUS.IS_NUMBER;
}
break;
case IS_KEYWORD:
if (Character.isLetterOrDigit(c)) {
mToken += c;
}
else {
mStatus = STATUS.START;
System.out.println("keyword: " + mToken);
mToken = "";
}
break;
case IS_NUMBER:
if (Character.isDigit(c)) {
mToken += c;
}
else {
mStatus = STATUS.START;
System.out.println("number: " + mToken);
mToken = "";
}
break;
}
}
}
}
public class ClassicalMachine implements Parser {
private BufferedReader mFin;
private String mToken;
public ClassicalMachine( BufferedReader fin ) {
mFin = fin;
}
private enum STATUS {START, IS_KEYWORD, IS_NUMBER};
STATUS mStatus = STATUS.START;
@Override
public void parse() throws Exception {
mToken = "";
while (true) {
int ch = mFin.read();
if (-1 == ch) break;
char c = (char)ch;
switch (mStatus) {
case START:
if (Character.isLetter(c)) {
mToken += c;
mStatus = STATUS.IS_KEYWORD;
}
else if (Character.isDigit(c)) {
mToken += c;
mStatus = STATUS.IS_NUMBER;
}
break;
case IS_KEYWORD:
if (Character.isLetterOrDigit(c)) {
mToken += c;
}
else {
mStatus = STATUS.START;
System.out.println("keyword: " + mToken);
mToken = "";
}
break;
case IS_NUMBER:
if (Character.isDigit(c)) {
mToken += c;
}
else {
mStatus = STATUS.START;
System.out.println("number: " + mToken);
mToken = "";
}
break;
}
}
}
}
abstract class State {
public abstract void isAlpha(char c);
public abstract void isDigit(char c);
public abstract void isOther(char c);
public void dispatch(char c) {
if (Character.isLetter(c)) {
isAlpha(c);
}
else if (Character.isDigit(c)) {
isDigit(c);
}
else {
isOther(c);
}
}
}
class StartState extends State {
public void isAlpha(char c) {
setState( mKeywordState );
mToken += c;
}
public void isDigit(char c) {
setState( mNumberState );
mToken += c;
}
public void isOther(char c) {
}
}
class KeywordState extends State {
public void isAlpha(char c) {
mToken += c;
}
public void isDigit(char c) {
mToken += c;
}
public void isOther(char c) {
setState( mStartState );
System.out.println("Keyword: " + mToken);
mToken = "";
}
}
class NumberState extends State {
public void isAlpha(char c) {
setState( mStartState );
System.out.println("Number: " + mToken);
mToken = "";
}
public void isDigit(char c) {
mToken += c;
}
public void isOther(char c) {
setState( mStartState );
System.out.println("Number: " + mToken);
mToken = "";
}
}
public void parse() throws Exception {
while (true) {
int ch = mFin.read();
if (-1 == ch) break;
char c = (char)ch;
mState.dispatch( c );
}
}